Was there really a big problem with AWS in the Middle East in 2026? Yes. According to official entries on the Amazon Service Health Dashboard and global tech news, a data center in the United Arab Emirates experienced an unprecedented issue that led to a complete shutdown.
This event directly impacted thousands of businesses that depend on cloud stability for their daily operations.
When the Cloud Stood Still
Think about making a global e-commerce site or a fintech app that only works with Amazon Web Services. All of a sudden, people in the Middle East say they can't get in. You look at your dashboard and see that your Elastic Compute Cloud (EC2) instances aren't working.
API calls that have to do with networking, like giving out IP addresses, never work. This was the messy truth on March 1, 2026. We used to think of the cloud as something that couldn't be seen or beaten, assuming it would always be there regardless of the physical world.
This disruption, however, shows that even the most advanced digital ecosystems are connected to physical things such as bricks, mortar, and power lines. We'll use real data instead of rumors in this article to show how a power outage in one part of the Middle East hurt the digital economy.
Change: The Old Way vs. The Strong Way
Traditional cloud management often ignores the physical vulnerabilities of data centers. Below is a comparison of how business resilience is transforming.
The Old Way: If you only use one cloud region for all of your work and there is a fire or power outage there, your business will be completely shut down. This will hurt your reputation and cost you a lot of money.
The New Way (Hoplon Insight): Using multi-region architecture and real-time threat monitoring to quickly find local disasters, switch to a different geographic region, and keep providing service without any downtime.
We often think that a big company like AWS can't fail, but old-fashioned backup methods don't always take into account things like fires or the power grid going down. This is where companies like Hoplon Infosec that offer specialized solutions and modern cyber resilience come in very handy.
-20260302085515.webp)
The Root Cause: A Clear Look at What Went Wrong
In the UAE's early morning hours, workers in the AWS me-central-1 region, specifically in Availability Zone mec1-az2, ran into a big problem. Some reports that have been looked at say that things hit the building or the area around it. AWS has stayed out of politics, but the fire at the data center did a lot of damage.
Firefighters from the area got there quickly to make sure everyone was okay. It was smart of them to ask for the building's power to be turned off completely. This meant shutting off the main power grid and the backup diesel generators. When a data center loses all of its power sources, it goes dark. This made thousands of virtual machines crash and stopped any new services from starting.
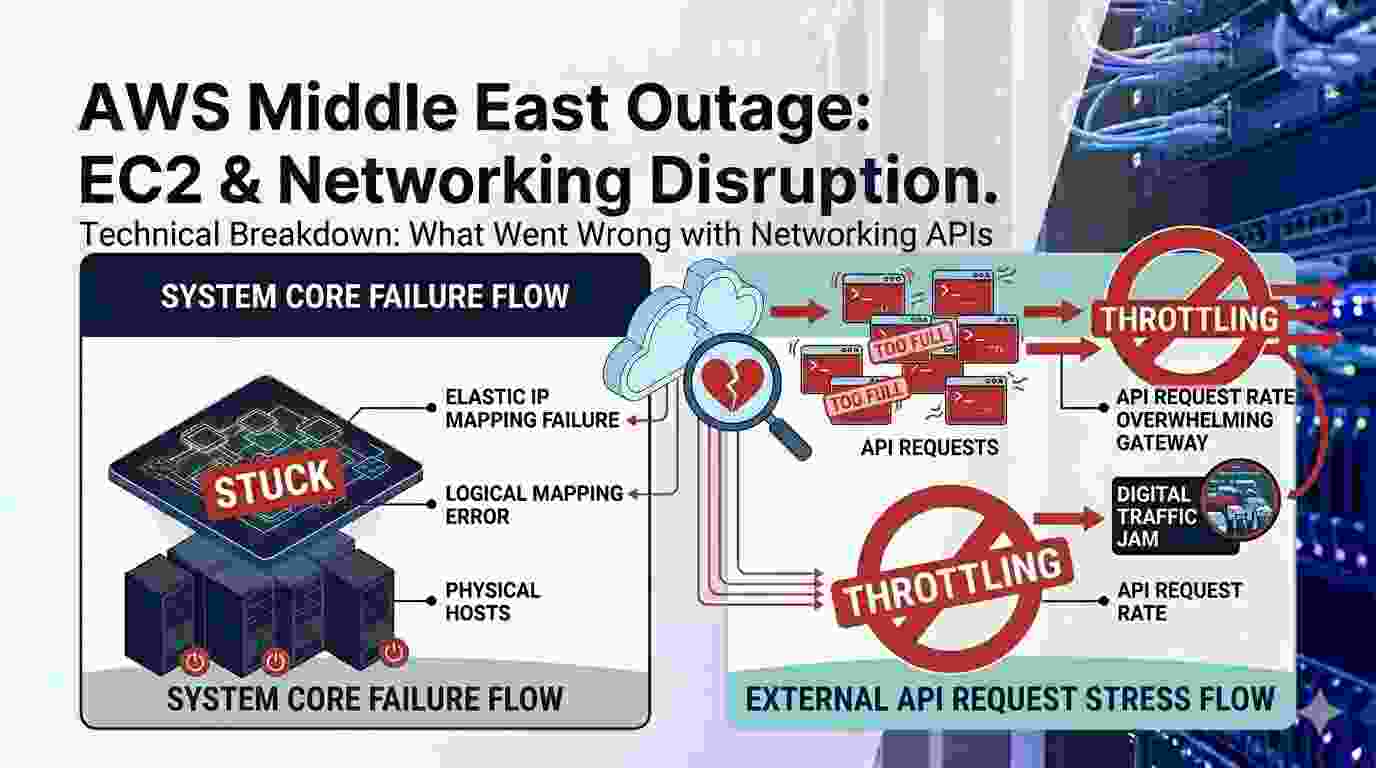
Technical Breakdown: What Went Wrong with Networking APIs
Many people didn't get why some networking services, like AllocateAddress or AssociateAddress, were also having trouble with the servers. The control plane gets stuck when physical hosts lose power and Elastic IPs can't be logically mapped.
The code isn't the only thing wrong. It is a big break in the chain of command. AWS said that the management console in that area was too full. The API request rate went up when thousands of automated scripts tried to restart servers all at once. This caused a lot of throttling to happen. The gateway couldn't handle all the recovery attempts, so it was like a digital traffic jam.
Who Was Most Affected by the Disruption?
The disruption was like a line of dominoes falling, and it hurt a lot of businesses across various sectors:
Startups in the Area: A lot of businesses in Dubai or Bahrain kept their main databases in the Middle East and were offline for a few hours.
Global Businesses: Big companies that used the Middle East node to send data quickly to local users saw huge increases in lag or total connection timeouts.
IT Operations Teams: DevOps engineers had to deal with a nightmare situation where the AWS console wouldn't respond, which made it impossible to fix things by hand.
The physical infrastructure fell apart. When this happens, the Recovery Time Objective (RTO) is usually much longer because you can't just fix a power transformer or a building that doesn't have power with a simple software patch.
The Fintech Survival Story: A Real-Life Example
Imagine a popular payment gateway in Dubai that had all of its servers in the AWS Middle East area. They couldn't finish any transactions on the morning of March 1.
Before: They didn't have any backups that were made automatically in different places. Because of this, they stayed completely dark for more than six hours, losing thousands of dollars every minute.
After (The Answer): After that, they talked to Hoplon Infosec about how to change the way their systems work. Their main servers are still in the Middle East, but they also have a second hot backup that is synced with servers in either Europe or the Asia Pacific region.
If the Middle East goes dark again, their traffic will change direction on its own in five minutes.
3 Critical Steps to Keep Your Business Safe Right Now
If you make decisions for your business, you need to do these three things:
Multi-Availability Zone Strategy: Don't put all of your resources in one AZ. Store your data in at least two or three zones so that problems in one building don't affect it.
Global Backups: Make sure you have an encrypted copy of your most important data on a different continent, like North America or Europe.
Infrastructure as Code (IaC): Use tools like Terraform and CloudFormation. If something goes wrong, you can use scripts to set up your whole server environment in a new area instead of doing it by hand.
Hoplon Infosec is very good at figuring out these complicated cloud setups. They do more than just get everything ready to keep your business safe from both cyber threats and natural disasters that damage your physical infrastructure.
Frequently Asked Questions (FAQ)
1. Did a cyberattack cause the AWS Middle East outage? No. Official records show that property was damaged and a fire caused the power to go out completely. There is no proof that a hack or data breach happened.
2. Is my information safe now that the power is out? AWS has said that this was a problem with availability. When servers went down, the data on S3 or EBS volumes was usually safe until power came back on.
3. Why did it take so long to get back on? For fire safety, engineers have to check every electrical circuit before they can turn the servers back on. This is to stop more damage or fires in hardware from happening.
4. How can I keep track of these issues as they come up? Set up CloudWatch alarms to let you know right away when the API error rates start to rise, and always check the AWS Personal Health Dashboard.
In short
• A modern cloud strategy should include more than just software-based security; it should also include threats to people and places.
• By planning across several regions, you can make sure that your business stays online even if a whole data center goes down.
• Hoplon Infosec does cloud audits and disaster recovery for businesses that want to keep their digital assets safe no matter where they are.
You can trust the AWS Service Health Dashboard to give you good information.
"In an unstable geopolitical climate, cloud resilience is no longer a luxury but a basic business need," says a research quote. Gartner Cloud Security Report 2026
Recommendations
• Chaos Engineering: Use it to find out what happens when you can't get to a whole area.
• Latency Monitoring: Watch the Networking API's latency to see if the area is unstable before a full crash happens.
• Stateless Apps: Create stateless apps to make it easier to move data between regions and less likely that it will be lost.
For more latest updates like this, visit our homepage.

-20260721112851.webp&w=3840&q=75)