
At a Glance: AI vulnerability discovery and patching
| Element | Detail |
|---|---|
| Initiative | OpenAI Daybreak (launched May 10, 2026; expanded June 23, 2026) |
| Core Specialized Model | GPT-5.5-Cyber |
| CyberGym Score | 85.6% (GPT-5.5: 81.8% / Mythos 5: 83.8% / Claude Opus 4: 73.1%) |
| ExploitGym Score | 39.5% vs. 25.95% for GPT-5.5 |
| SEC-bench Pro Score | 69.8% vs. 63.1% for GPT-5.5 |
| Codex Security Impact | 30M+ commits scanned; 30,000+ codebases; 70,000+ findings fixed; 500,000+ auto-resolved |
| Enterprise Partners | Akamai, Cisco, Cloudflare, CrowdStrike, Fortinet, Oracle, Palo Alto Networks, Zscaler |
| Open Source Initiative | Patch the Planet (Trail of Bits + HackerOne + Calif) |
| Threat Context | 44% YoY increase in public-facing app attacks; 89% surge in AI-enabled adversary activity |
| Bug Bounty Reduction | Google reduced Chrome bounties due to AI-accelerated discovery volume |
Can one AI model find more vulnerabilities in a single day than a team of experienced security researchers can in several weeks? In 2026, that question is no longer theoretical. On June 23, 2026, OpenAI expanded its Daybreak cybersecurity initiative by releasing the full version of GPT-5.5-Cyber to trusted defenders, alongside a major update to its Codex Security plugin and a new open-source security initiative called Patch the Planet. The announcement confirmed what many in the security community had been quietly watching for months: AI vulnerability discovery and patching has crossed a threshold that changes how enterprises, developers, and open-source maintainers need to think about software security.
This article is a complete guide to understanding what Daybreak actually is, how GPT-5.5-Cyber works under the hood, what the Codex Security plugin can do today, and what all of this means for your security program. It covers the technical architecture, real benchmark data, verified vulnerability findings, the Squidbleed case study, the offensive AI threat landscape, and practical guidance for implementing these capabilities in your organization.
What is OpenAI Daybreak and Why Does It Exist?
OpenAI named this initiative Daybreak deliberately. The name refers to "the first glimpse of sunlight in the morning," which is meant to represent seeing security risk earlier and acting on it before attackers do. That framing captures the initiative's actual mission better than most coverage has.
Daybreak is not a product launch in the traditional sense. It is a structured program that bundles frontier AI models, an agentic coding harness, a layered access model, and a network of security partners into a coordinated effort aimed at defenders. The core problem it is trying to solve is a shift that has been building for several years. AI can now find vulnerabilities faster than human teams can patch them. The bottleneck in software security has moved. It used to be discovery. Now it is remediation.
The initiative launched on May 10, 2026, and expanded significantly on June 23. Sam Altman framed the ambition plainly at launch: "AI is already good and about to get super good at cybersecurity; we'd like to start working with as many companies as possible now to help them continuously secure themselves."
Daybreak operates on three model tiers. The first is GPT-5.5, the standard model with normal safeguards, used for most defensive workflows including code review, vulnerability assessment, malware analysis, and detection engineering. The second is GPT-5.5 with Trusted Access for Cyber, which is GPT-5.5 with access controls that allow it to be used in verified defensive environments. The third is GPT-5.5-Cyber, which is a permissive model purpose-built for authorized red teaming, penetration testing, and controlled validation workflows. These are not the same model offered at different pricing tiers. They are architecturally differentiated in terms of what they are permitted to do.
GPT-5.5-Cyber: Benchmarks, Capabilities, and How Access Works
GPT-5.5-Cyber is the most capable and most restricted tier in the Daybreak stack. It is not available through a standard API subscription. Access requires identity verification, named-user accountability, scope controls, and human oversight requirements. OpenAI treats it less like a product and more like privileged infrastructure.
The model's safety training built on a progression starting with GPT-5.2, expanded through GPT-5.3-Codex and GPT-5.4, and culminating in both GPT-5.5 and GPT-5.5-Cyber. Alongside the model itself, Daybreak runs automated classifier-based conversation monitors that detect signals of suspicious cyber activity and route high-risk traffic to a less capable model tier.
The benchmark numbers tell a clear story about where GPT-5.5-Cyber sits relative to competing models.
| Benchmark | GPT-5.5-Cyber | Mythos 5 | Claude Opus 4 | GPT-5.5 |
|---|---|---|---|---|
| CyberGym | 85.6% | 83.8% | 73.1% | 81.8% |
| ExploitGym | 39.5% | Not published | Not published | 25.95% |
| SEC-bench Pro | 69.8% | Not published | Not published | 63.1% |
CyberGym tests whether an AI agent can reproduce known vulnerabilities in controlled software environments. It measures the model's ability to understand a vulnerability, navigate a codebase to find it, and demonstrate reproduction in a sandboxed context. GPT-5.5-Cyber's 85.6% score is the highest publicly recorded on this benchmark.
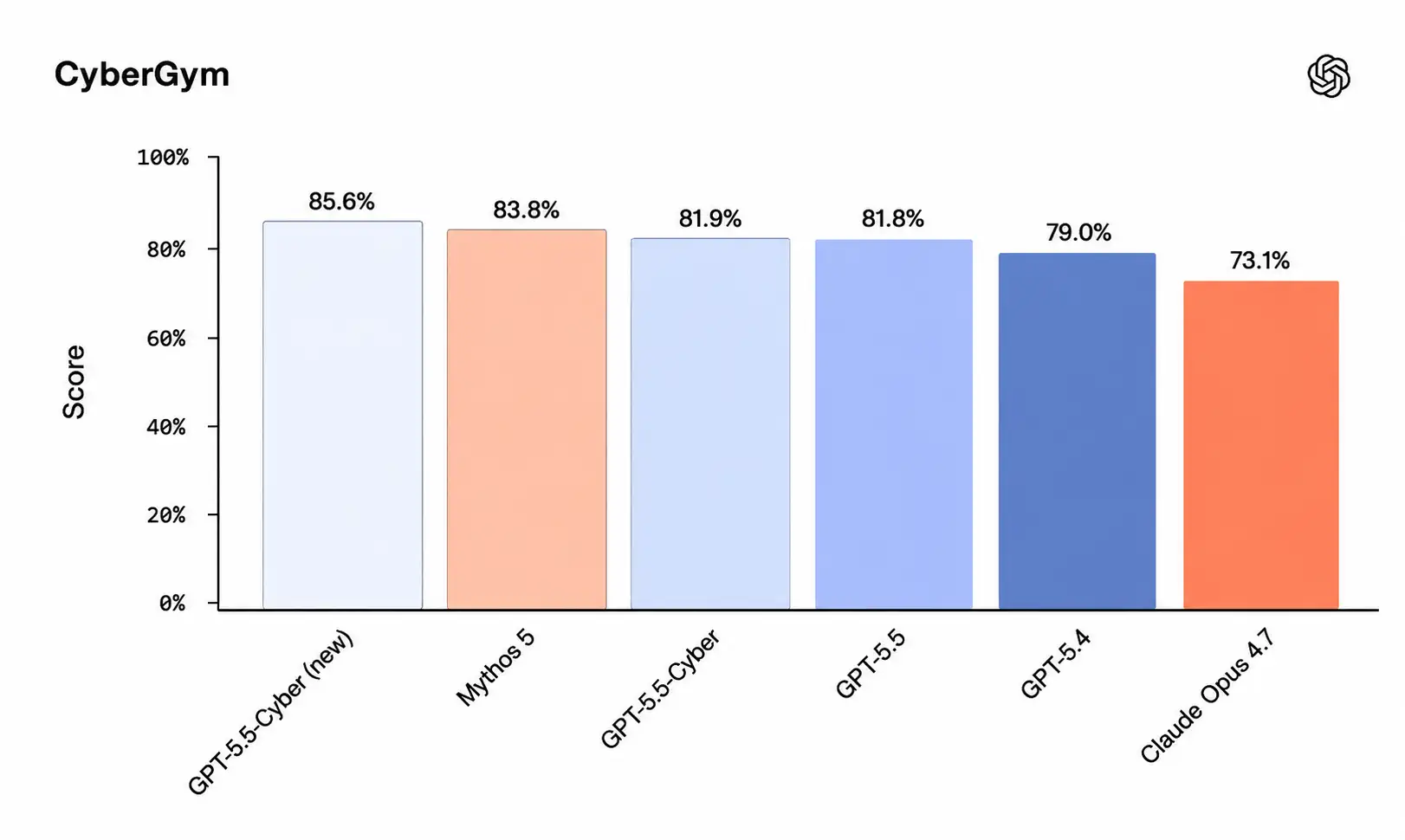
ExploitGym goes further. It measures whether a model can take a known vulnerability and convert it into a working exploit that achieves unauthorized code execution. GPT-5.5-Cyber scored 39.5% versus GPT-5.5's 25.95%, a meaningful gap that reflects the specialization built into the cyber-specific model.
SEC-bench Pro tests long-horizon vulnerability discovery and proof-of-concept generation across genuinely complex software targets. A score of 69.8% on that benchmark represents capability that, eighteen months ago, would have been described as aspirational.
OpenAI is also collaborating with the Center for AI Standards and Innovation on pre-deployment testing for both GPT-5.5 and GPT-5.5-Cyber, and has been working with the Office of the National Cyber Director and the Office of Science and Technology Policy on implementation of the June 2026 AI Executive Order. That government engagement is not background detail. It shapes what the models are permitted to do and what governance structures surround deployment.
Codex Security: The Agentic Harness That Makes This Practical
GPT-5.5-Cyber is the headline, but the tool that most security teams will actually use is the Codex Security plugin. It has had a long development path. It entered private beta in late 2025, moved to research preview in March 2026, and received a significant update alongside the June 23 Daybreak expansion.
The core workflow is worth understanding in detail. Codex Security starts by building an editable threat model for a given repository. It focuses that model on realistic attack paths and high-impact code rather than scanning everything equally. It then validates likely vulnerabilities in an isolated environment, so security teams can prioritize reproducible issues over noisy alerts. From there it generates codebase-specific patches for human review. The human does not leave the loop. The model accelerates the loop.
What developers can actually do with the plugin is substantial. They can run deep scans or review recent code changes. They can generate reports with severity rankings, affected code locations, validation evidence, and remediation guidance. They can trace attack paths, build threat models, validate findings, and produce codebase-specific patches ready for review. The system also triages and validates existing findings from external scanners, advisories, bug bounty reports, and ticketing systems, and can facilitate patch generation at scale to close a backlog.
Export options include SARIF, CodeQL, Codex CLI, the Codex app, and existing vulnerability management platforms, making it integrable with workflows most enterprise security teams already run.
The measured impact since the March 2026 research preview is significant. Codex Security Cloud has scanned more than 30 million commits across more than 30,000 codebases. Human reviewers have confirmed more than 70,000 findings as fixed. The platform has automatically verified over 500,000 additional fixes. Those numbers represent an order-of-magnitude improvement in vulnerability management throughput that no comparable point-in-time scanner can match.
The key architectural difference from tools like CodeQL or GitHub Copilot is that Codex Security runs a continuous, agentic loop rather than a one-time scan. It maintains a living threat model for a repository. When dependencies update, new features ship, or configurations drift, it re-evaluates attack surfaces and flags emerging risks. That is a fundamentally different model than running a static analysis tool at pull request time.
Patch the Planet: How OpenAI is Trying to Fix Open Source Security
Patch the Planet is the most ambitious piece of the Daybreak expansion, and also the least understood. It is an initiative built with Trail of Bits, in collaboration with HackerOne and Calif, specifically to help widely used open-source projects move from vulnerability findings to actual shipped fixes.
More than 30 open-source projects have committed to participate. Initial participants include cURL, NATS Server, pyca/cryptography, Sigstore, aiohttp, the Go project, freenginx, Python, and python.org. Trail of Bits committed their entire security research organization toward the initial surge, which is a significant resource commitment from one of the most respected security engineering firms in the industry.
What Trail of Bits built in partnership with OpenAI consists of two reusable pipeline mechanisms. The first is an automated lab setup capability. GPT-5.5-Cyber was able to build a complete fuzzing and analysis environment for a target project in less than one day. Trail of Bits estimates that building the same lab manually would ordinarily take at least several weeks. That compression in setup time is not trivial. It means the per-project cost of running a serious security audit drops dramatically, which makes it feasible to cover more of the open-source ecosystem.
The second mechanism is a CVE variant pipeline. It ingests historical CVEs, extracts the relevant vulnerability patterns, searches target codebases for related flaws, deduplicates results, filters likely false positives, and routes the strongest evidence to security engineers for manual confirmation. This turns years of public vulnerability history into a repeatable search strategy that can be applied across projects continuously, not just once.
The human review model matters here. Security engineers validate findings before they reach maintainers. The goal is to reduce burden on maintainers, not add to it. The full loop runs discovery, validation, severity review, coordinated disclosure, patch development, testing, and deployment, with the post-fix goal of building reusable workflows that continue improving security after initial fixes land.
One outcome from this work is particularly worth noting. GPT-5.5 discovered CVE-2026-8390, a WebAssembly vulnerability in Mozilla Firefox, during safety evaluations. Mozilla patched it two days before Pwn2Own Berlin. When the competition started, five of six registered Firefox entries withdrew. No Firefox exploit was successfully demonstrated at the competition. That outcome is a direct consequence of AI-assisted vulnerability discovery and patching accelerating the defensive side of the disclosure timeline.

The Daybreak Cyber Partner Program: How Enterprise Access Actually Works
For most enterprise security teams, access to Daybreak capabilities will come through a partner rather than directly from OpenAI. The Daybreak Cyber Partner Program enables security software vendors and service providers to integrate GPT-5.5 with Trusted Access for Cyber into the products they deliver to customers.
Named launch partners include Akamai, Cisco, Cloudflare, CrowdStrike, Fortinet, Oracle, Palo Alto Networks, and Zscaler. These are not passive logo relationships. Partners are collaborating with OpenAI to strengthen safeguards, monitoring, and abuse-prevention standards needed to deploy these capabilities responsibly across the security ecosystem.
What partners can build on top of this access is broad. AI-powered code review, vulnerability assessment, malware analysis, detection engineering, and patch validation workflows can all be embedded in partner products. Direct model access stays with partners. Customers benefit through those partner products rather than directly querying GPT-5.5-Cyber themselves.
For organizations that want direct access, the tiered structure runs from Codex Security's free scan capability through team-level access to an enterprise tier that includes advanced model access, custom integrations, compliance review, and rollout planning with OpenAI cyber experts.
| Access Tier | Best For | Capabilities |
|---|---|---|
| Free | Trying the workflow, reviewing a branch, investigating one codebase | Basic scanning, limited integrations |
| Team | Security teams scanning multiple codebases | Full Codex Security Cloud, SARIF export, advisory triage |
| Enterprise | Large fleets, compliance needs, custom deployments | Advanced model access, CI/CD integration, partner coordination |
| Trusted Access for Cyber | Verified defenders requiring permissive capabilities | GPT-5.5-Cyber via partner program or direct verification |
What Daybreak Has Already Found: Full Vulnerability Inventory
The Daybreak initiative has already produced a significant body of real findings across multiple operating systems, browsers, and network infrastructure components. These are not theoretical demonstrations. They are coordinated disclosures of actual vulnerabilities.
| Target | Finding | Technical Context |
|---|---|---|
| Linux Kernel | 8 kernel pointer info leak PoCs | GPT-5.5-Cyber analyzed 30M+ lines of code; dynamic validation after static flagging |
| Linux Kernel | 24 local privilege escalation exploits | Validated in isolated environments |
| OpenBSD | 23-year-old use-after-free | In kernel implementation of System V semaphores |
| FreeBSD | 34 vulnerabilities + 7 LPE PoCs | Multiple component areas |
| dnsmasq | 6 vulnerabilities (CVE-2026-4890, 4891, 4892, 5172) | Network-level DNS/DHCP exposure |
| HTTP/2 implementations | HTTP/2 Bomb DoS technique | Affects NGINX, Apache, IIS, Pingora |
| Chrome V8 | 5 exploitable vulnerabilities | JavaScript engine; found by Codex Cyber |
| Apple Safari | 10 exploitable vulnerabilities | Multiple engine components |
| Mozilla Firefox | CVE-2026-8390 (WebAssembly) | Patched pre-Pwn2Own; no exploit demonstrated at competition |
The Linux kernel analysis required GPT-5.5-Cyber to navigate more than 30 million lines of code, identify security-relevant components, flag potential issues, and then validate them dynamically. That is not a task any manual review process could scale to cost-effectively.
The HTTP/2 Bomb finding deserves brief explanation because it represents a different class of risk. This is a denial-of-service technique that exploits the way HTTP/2 handles stream multiplexing. By sending crafted frames that cause server-side resource allocation to balloon, an attacker can take major HTTP/2 implementations offline. The fact that it affects NGINX, Apache, IIS, and Pingora simultaneously means the blast radius of a coordinated attack using this technique is broad.
The OpenBSD use-after-free is a 23-year-old bug in the kernel's implementation of System V semaphores, a memory synchronization mechanism inherited from Unix. Use-after-free bugs in kernel memory management are among the most dangerous classes of vulnerabilities because they can be leveraged for local privilege escalation, allowing an attacker who already has limited system access to gain full control. The fact that this bug survived 23 years of audits is a data point about what AI-assisted analysis enables that human review cannot replicate at scale.
More findings are still in coordinated disclosure, and OpenAI has committed to publishing deeper technical reports as those disclosures conclude.
Case Study: Squidbleed and Why AI Found What 30 Years of Audits Missed
One of the most instructive examples of AI vulnerability discovery changing what is possible comes not from OpenAI's tools but from Anthropic's Claude Mythos Preview, used by Calif Security Research. It is worth covering in depth because it illustrates exactly why AI-assisted analysis succeeds where traditional methods fail.
Squidbleed, tracked as CVE-2026-47729, is a heap buffer overread in Squid Proxy's FTP directory listing parser. It leaks previous users' uncleared HTTP request data, including Authorization headers, session cookies, API keys, and sensitive tokens. Calif discovered it using Claude Mythos Preview, which, as the Calif team noted, "spotted the bug almost immediately when pointed at the right code."
The technical root cause traces back to a commit from January 18, 1997. That commit added logic to handle FTP servers running on NetWare, which placed four spaces between a file's modification timestamp and its filename. The handling code used strchr(w_space, *copyFrom) to skip whitespace characters. The problem is that strchr in C does not check for a null terminator before scanning. When the null byte at the end of a string is reached, strchr searching for a whitespace character continues past it, reading into adjacent heap memory. That memory belongs to a previous user's HTTP request that was never cleared.
The one-line fix is to add a null check before calling strchr:
- while (strchr(w_space, *copyFrom))
+ while (*copyFrom && strchr(w_space, *copyFrom))
That is a genuinely trivial change once you understand the bug. The hard part was connecting three independently unremarkable facts: a 1997 compatibility shim for a defunct network operating system, the C standard's specific behavior for strchr with a null byte, and an internal allocator reuse behavior that is documented nowhere near the parsing code that depends on it. None of those facts is dangerous in isolation. Their conjunction creates a cross-tenant data leak that survived three decades of security audits.
An AI model can hold all three pieces of context simultaneously while tracing through the code. A human auditor reviewing the FTP parser in isolation has no reason to connect it to allocator behavior documented in a different part of the codebase.
Exploitability requires an attacker to control an FTP server reachable from the proxy on TCP port 21, and the proxy must be handling cleartext HTTP or operating in a TLS-terminating configuration. The highest-risk environments are shared proxies in corporate networks, schools, and public Wi-Fi hotspots, where multiple users route traffic through the same Squid instance.
Squid maintainer Amos Jeffries posted a correction to the oss-sec mailing list clarifying that Squid 7.6 does not include the Squidbleed fix. Squid 7.6 addresses a separate vulnerability, CVE-2026-50012, a heap overflow in cache_digest reply handling. The actual CVE-2026-47729 fix ships in Squid 7.7, which had not yet been released as of disclosure. The interim mitigation is to remove port 21 from the Safe_ports list in squid.conf and restart Squid.
The Offensive AI Threat Landscape: What Defenders Are Actually Facing
The Daybreak initiative exists because the offensive side of this equation is accelerating just as fast. Understanding the threat context is not optional for any security team trying to make decisions about where to invest.
IBM's X-Force 2026 Threat Intelligence Index reported a 44% year-over-year increase in attacks targeting public-facing applications, with the surge directly attributed to AI-enabled vulnerability discovery. CrowdStrike's 2026 Global Threat Report logged an 89% increase in attacks by AI-enabled adversaries year over year. These are not marginal shifts. They represent a fundamental change in the economics of offensive operations.
HackerOne paused its public bug bounty program in March 2026, citing the sheer volume of AI-generated findings and triage fatigue from hallucinated reports. The volume of AI-produced submissions had outpaced the capacity of human triagers to evaluate them.
The Canadian Centre for Cyber Security issued guidance in May 2026 stating that organizations should assume AI-driven exploitation may bypass preventative controls, significantly outpace vendors' capacity to publish corrective measures, and challenge the organization's ability to deploy fixes. That is official government guidance acknowledging that traditional patch management timelines are no longer adequate.
Intelligence agencies from Australia, Canada, New Zealand, the United Kingdom, and the United States issued a joint warning stating that frontier AI models are anticipated to exceed current industry expectations, and that the timeline is months, not years.
One concept worth defining clearly is vibe-coded exploits. This term refers to LLM-generated exploit code produced by threat actors who lack deep technical expertise but can prompt AI models to produce working attack code. The barrier to exploit development is dropping. Attackers no longer need to understand memory corruption internals to weaponize a published vulnerability. They need only a capable model and a published CVE. This is compressing the window between vulnerability disclosure and active exploitation to near zero.
For organizations running AI-driven automated red teaming programs, this context shapes what the simulated attacks need to look like. The adversary model has changed, and the red team methodology needs to reflect that change.
How OpenAI is Governing This: Safety Infrastructure and Access Controls
It is worth being explicit about what GPT-5.5-Cyber is not. It is not an open API endpoint. It is not available to anyone who creates an OpenAI account. Calling it a product in the conventional sense is misleading.
The three-tier access model carries meaningful differences. The general tier uses standard safeguards designed for broad use. The Trusted Access for Cyber tier applies to verified defensive work in authorized environments, with named-user accountability, logging, scope controls, and verification requirements. The permissive tier, GPT-5.5-Cyber itself, adds additional controls appropriate for the most sensitive defensive workflows, including authorized red teaming and penetration testing contexts.
Automated classifier-based conversation monitors run continuously, detecting signals of suspicious cyber activity and routing high-risk traffic to a less cyber-capable model. These classifiers were developed through the safety training progression that started with GPT-5.2 and matured through each subsequent version.
OpenAI has been in dialogue with the U.S. government throughout this process, specifically with CAISI for pre-deployment testing, and with the ONCD and OSTP on implementation of the June 2026 AI Executive Order. That coordination is not ceremonial. It shapes what the models are permitted to do and what the access controls must look like.
For virtual CISO services providers advising clients on AI adoption in security workflows, the governance architecture matters as much as the capability. Clients need to understand they are not getting a free-form AI that they can use however they want. They are getting access to scoped defensive capability with accountability built in.
-20260623082705.webp "AI vulnerability discovery and patching")
How to Actually Implement Daybreak in Your Organization
The entry point for most organizations is not GPT-5.5-Cyber. It is GPT-5.5 with Codex Security. That combination handles most defensive security workflows without requiring the verified access process that the more permissive model demands.
For teams starting from scratch, the practical path looks like this. Request a vulnerability scan through the Codex Security Cloud free tier to understand what the tool surfaces in one codebase. From there, evaluate the team tier if the volume of findings and the export format support your existing workflow. For enterprise deployments with compliance requirements, the enterprise tier includes rollout planning with OpenAI cyber experts. For teams that need the most advanced capabilities, applying through a Daybreak Cyber Partner Program member such as CrowdStrike or Palo Alto Networks may be the most practical path to Trusted Access.
Integrating Codex Security into a CI/CD pipeline is straightforward for teams already using SARIF-compatible tooling. The Codex CLI and CodeQL export options connect to most existing vulnerability management platforms without requiring significant workflow changes.
What Codex Security does not replace is human judgment. Findings still require validation. Patches generated by the model require review before deployment. The coordinated disclosure process for serious findings still requires human involvement. The model accelerates the loop. It does not close it autonomously.
For open-source maintainers interested in joining Patch the Planet, the engagement model is collaborative rather than extractive. Security engineers from Trail of Bits and OpenAI review findings before they reach maintainers, develop patches and tests alongside the project team, and build reusable workflows. The goal is to improve security after the initial fixes land, not just produce a disclosure report.
For penetration testing teams looking to understand how these capabilities integrate with existing red team workflows, the key distinction is that Daybreak is built for the defensive remediation loop, not for offensive simulation. The AI-driven automated red teaming use case has a different access pathway and different governance requirements.
AI Cybersecurity Tools in 2026: Where Daybreak Sits
| Tool | Developer | Model | Access | Primary Use | CyberGym |
|---|---|---|---|---|---|
| Daybreak / GPT-5.5-Cyber | OpenAI | GPT-5.5-Cyber | Verified defenders | Full remediation loop | 85.6% |
| Mythos Preview | Anthropic | Claude Mythos | Trusted orgs only | Offensive + defensive research | 83.8% |
| Codex Security | OpenAI | GPT-5.5 | General + enterprise | AppSec in CI/CD | 500K+ auto-resolved |
| GitHub Copilot Autofix | GitHub / OpenAI | GPT-4o | General | Code suggestion, basic fix | Not published |
| CodeQL | GitHub | Static analysis | Open source + enterprise | SAST | Not applicable |
Anthropic's Mythos Preview is worth brief context. It is currently restricted and not available to the general public. A U.S. order has suspended foreign national access. It is used by a limited set of trusted organizations. The Squidbleed discovery came from Calif using Mythos Preview in that restricted context.
The key differentiator between Daybreak and all other options in this table is that Daybreak is agentic and continuous. Every competitor is largely point-in-time. CodeQL runs at scan time. Copilot Autofix triggers on pull requests. Daybreak maintains a living threat model that updates as the codebase evolves. That architectural difference is not a marketing claim. It is a meaningful technical distinction that changes what the tooling can catch and when it can catch it.
What This Means for Enterprise Security Strategy in 2026
The Five Eyes warning that frontier AI models will exceed current expectations on a timeline of months, not years, is not a hypothetical risk assessment. It is a description of where the industry is right now, based on what has already happened.
For CISOs, the practical implication is that patch SLAs built around the assumption of a several-week window between vulnerability discovery and exploitation are no longer defensible. The attack window is compressing. AI vulnerability discovery and patching on the defensive side is the mechanism to match that compression.
AI generates more valid findings than human teams can review. This creates a new triage problem. The solution is not to ignore findings, which creates attack surface management gaps. The solution is prioritization tooling that ranks by CVSS score, EPSS probability, and CISA KEV status simultaneously, combined with partner-mediated access to AI-powered validation that can filter false positives before they reach human reviewers.
For organizations operating under CMMC, SOC 2, or PCI requirements, the June 2026 AI Executive Order creates emerging compliance obligations around how AI is used in security workflows. Working with your security compliance advisors to understand where Daybreak-class tooling fits in your control framework is not a future consideration. It is a current one.
The line between feature development and security engineering is dissolving. Shift-left has been discussed as a philosophy for years. AI vulnerability discovery and patching is the mechanism that makes it operational rather than aspirational.
Hoplon Insight Box
Recommendations from Hoplon InfoSec:
Start your Daybreak evaluation with Codex Security on a single high-risk codebase before attempting a broader rollout. The most common failure mode in AI security tool adoption is deploying to everything at once, getting overwhelmed by findings volume, and reverting to prior workflows. Pick one application that handles sensitive data, run a full scan, and work through the validation and remediation loop end to end. That process reveals your actual triage capacity and integration gaps before you scale.
For organizations that want independent guidance on how AI vulnerability discovery tools fit into their existing control environment, Hoplon InfoSec's gap assessment service provides a structured starting point that maps current coverage against the AI-accelerated threat model that agencies and industry reports describe for 2026.
If your incident response and recovery plan was last updated before the AI acceleration in vulnerability discovery became measurable, it likely needs revision. The assumption that you have weeks between disclosure and exploitation is no longer reliable for many vulnerability classes.
Frequently Asked Questions
What is OpenAI Daybreak and how does it work? OpenAI Daybreak is a cybersecurity initiative that combines GPT-5.5 and GPT-5.5-Cyber models with the Codex Security plugin and a partner program to help organizations find, validate, and patch software vulnerabilities. It operates through a three-tier access model and is designed to close the full remediation loop from discovery through deployed fix, not just surface findings.
What is GPT-5.5-Cyber and who can access it? GPT-5.5-Cyber is a specialized AI model optimized for offensive and defensive security workflows, scoring 85.6% on CyberGym, the highest publicly recorded score. Access is restricted to verified defenders through a limited release program. Named-user accountability, authorization requirements, logging, and scope controls are required. Most organizations access it through Daybreak Cyber Partner Program members rather than directly.
How does Codex Security differ from GitHub Copilot or CodeQL? Codex Security runs a continuous, agentic loop that maintains a living threat model for a codebase and re-evaluates it as the code changes. CodeQL is a point-in-time static analysis tool. Copilot Autofix assists with code generation and basic fixes but does not run autonomous threat modeling or isolated environment validation. The architectural difference is that Codex Security is active and continuous, not triggered only at scan time.
What is the Patch the Planet initiative? Patch the Planet is an open-source security initiative founded with Trail of Bits and HackerOne. It pairs AI-assisted vulnerability discovery using GPT-5.5-Cyber with expert human review to help widely used open-source projects move from findings to shipped fixes. More than 30 projects including cURL, Go, Python, and Sigstore have committed to participate. Trail of Bits committed their entire security research organization to the initial surge.
What is a vibe-coded exploit? A vibe-coded exploit is attack code generated by an AI model on behalf of a threat actor who lacks deep technical expertise. The term captures how LLMs have lowered the barrier to exploit development. An attacker who cannot write memory corruption exploits from scratch can prompt a capable model to produce working attack code against a published CVE. This is compressing the time between vulnerability disclosure and active exploitation.
What is Squidbleed and is a patch available? Squidbleed, CVE-2026-47729, is a heap buffer overread in Squid Proxy's FTP directory listing parser that leaks previous users' HTTP request data including session tokens and API keys. It was discovered by Calif using Claude Mythos Preview. The fix is scheduled for Squid 7.7, which had not yet been released as of the initial disclosure. Squid 7.6 addresses a separate vulnerability, CVE-2026-50012. The interim mitigation is to remove port 21 from squid.conf Safe_ports and restart the service.
Is AI vulnerability discovery accelerating attacks as well as defenses? Yes. The same capabilities that help defenders find bugs faster also help attackers produce exploits faster. CrowdStrike reported an 89% year-over-year increase in AI-enabled adversary activity in 2026. The Five Eyes agencies warned that the timeline for AI to exceed current cyber threat expectations is months, not years. Defensive tools like Daybreak are designed to tilt that balance toward defenders, but the offensive acceleration is real and ongoing.
Official References
- OpenAI Daybreak landing page
- OpenAI Daybreak expansion announcement (June 23, 2026)
- OpenAI Patch the Planet initiative
- Calif Security Research, Squidbleed advisory
Ready to understand where your organization stands in this AI-accelerated threat environment?
The pace of vulnerability discovery has changed fundamentally, and the gap between when a flaw is found and when it gets exploited is narrowing every month. Hoplon InfoSec works with security teams to assess coverage, close gaps in remediation workflows, and build programs that match the actual threat timeline of 2026, not the one from three years ago. Start with a cyber resilience assessment and find out where your real exposure lies before someone else does.




-20260731111414.webp&w=3840&q=75)