Pickle in the Middle: How a Simple Bucket Naming Flaw in Vertex AI Led to Remote Code Execution
Inside the Google Vertex AI SDK vulnerability that enabled bucket squatting, model poisoning, credential theft, and cross-tenant compromise without ever touching the victim's project.
Article Summary
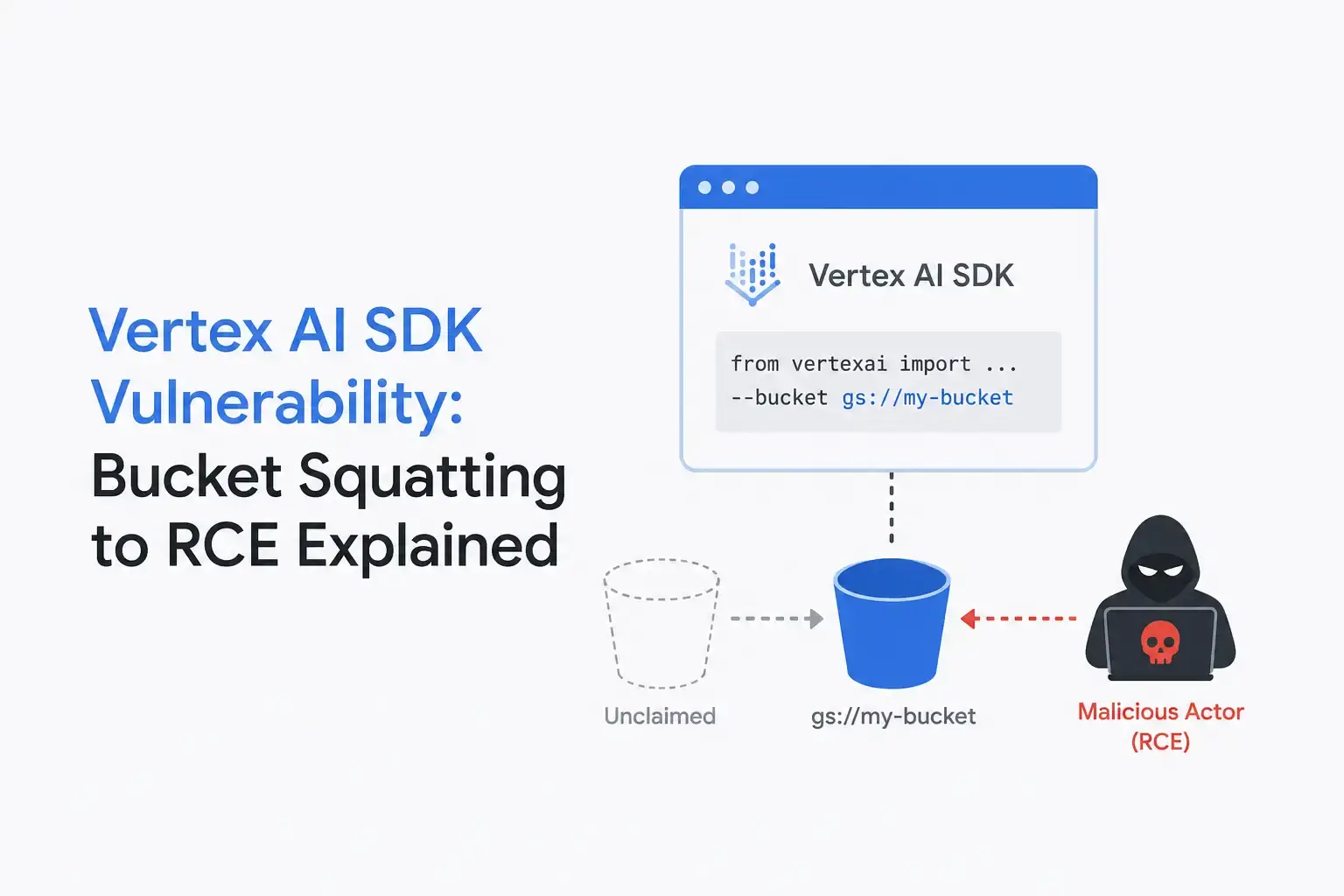
· Palo Alto Networks Unit 42 discovered a critical flaw in the Google Vertex AI Python SDK (google-cloud-aiplatform versions 1.139.0 and 1.140.0).
· The SDK generated predictable storage bucket names based solely on the victim's project ID and region: and never verified bucket ownership.
· An attacker armed with only a project ID could claim that bucket name first, intercept model uploads, and swap legitimate models with malicious ones.
· Python's pickle deserialization then executed attacker code automatically when Vertex AI loaded the model: resulting in full remote code execution (RCE).
· Post-exploitation access included OAuth token theft, BigQuery reconnaissance, GKE cluster visibility, and lateral movement across Google-managed tenant infrastructure.
· Google patched the issue in SDK v1.148.0 on April 15, 2026. All users should upgrade immediately and explicitly define staging buckets.
Table of Contents
2. Understanding the Vertex AI Ecosystem
3. Three Concepts You Must Understand First
4. How the Vulnerability Was Found
5. The Complete Attack Chain, Phase by Phase
6. What Happened After Code Execution
7. Five Security Design Failures Behind This Flaw
8. Google's Response and the Fix Timeline
9. What You Should Do Right Now
10. The Bigger Picture for AI Security
11. Official References
Why This Actually Matters
Most teams that build on managed AI platforms operate on a comfortable assumption: the cloud provider has sorted out the security. They provision Vertex AI, push a model, and get back to coding. The infrastructure piece feels handled.
That assumption is the setup for this story.
In early 2026, researchers from Palo Alto Networks' Unit 42 went looking for trust boundary problems inside AI infrastructure. What they found was not a theoretical edge case. It was a working attack that required no credentials, no phishing lure, and no foothold inside the victim's Google Cloud project. The attacker needed exactly one thing: the victim's project ID. That information is often completely public.
The result was a chain that went from a guessable bucket name all the way through to remote code execution, OAuth token theft, and lateral movement inside Google-managed infrastructure. The researchers named it Pickle in the Middle, a nod to both the Python serialization format at the heart of the exploit and the classic man-in-the-middle attack it resembles.
What makes this worth understanding is not just the specific bug. It is what the bug reveals: AI pipelines introduce entirely new attack surfaces where cloud infrastructure, machine learning artifacts, and the software supply chain all intersect. A small SDK design decision—one that a developer might spend three seconds reading before moving on—ended up being a path to compromising production AI workloads. This is precisely the kind of risk that cloud storage security strategies need to account for, and it is why attack surface management increasingly has to include the developer toolchain itself.
|
Attribute |
Detail |
|
Vulnerability Name |
Pickle in the Middle |
|
CVE |
CVE-2026-2473 (VertexSquat) |
|
Discovered By |
Palo Alto Networks Unit 42 |
|
Affected Versions |
google-cloud-aiplatform 1.139.0 and 1.140.0 |
|
Attack Type |
Bucket Squatting + Race Condition + Pickle Deserialization RCE |
|
Access Required |
Any GCP account + victim's project ID |
|
Platforms Affected |
Google Cloud Vertex AI (Python SDK) |
|
Reported to Google |
March 5, 2026 |
|
First Fix |
v1.144.0 - March 31, 2026 |
|
Final Fix |
v1.148.0 - April 15, 2026 |
|
Exploitation in Wild |
Not confirmed at time of disclosure |
Understanding the Vertex AI Ecosystem
Before getting into the attack, it helps to know how Vertex AI actually works when a developer ships a model.
Vertex AI is Google Cloud's managed machine learning platform. It handles the full lifecycle: training jobs, experiment tracking, model versioning through the Model Registry, and serving through online prediction endpoints. Data scientists and ML engineers use it because it removes a lot of the operational friction that comes with running ML workloads at scale.
When a developer wants to upload a local model say, a scikit-learn classifier or a TensorFlow checkpoint the typical workflow looks like this. They call Model.upload() through the Vertex AI Python SDK. Under the hood, the SDK needs somewhere to temporarily stage the model artifacts before Vertex AI's backend can pull them into the Model Registry. Somewhere is a Google Cloud Storage bucket.
If the developer has not explicitly told the SDK which bucket to use, the SDK picks one automatically. It constructs a name from the project ID and the region. Something like my-company-prod-vertex-staging-us-central1. This staging bucket is temporary infrastructure, a handoff point between the developer's machine and Google's serving layer.
Once the artifacts land in the staging bucket, a service account called the Platform Service Agent (P4SA) picks them up. This agent runs inside a Google-managed tenant project, a layer of infrastructure that is entirely hidden from the customer. The P4SA reads the artifacts, validates them, and deploys them into the serving container.
The whole thing is designed to be frictionless. And that frictionlessness, it turns out, had a serious cost.
Three Concepts You Must Understand First
The Pickle in the Middle attack chains together three distinct techniques. Understanding each one separately makes the full chain much easier to follow.
Bucket Squatting
Every Google Cloud Storage bucket must have a globally unique name. Not unique within your project. Unique across all of Google Cloud, for every customer, everywhere.
This is by design; it is what makes bucket URLs clean and predictable. But it creates a problem when bucket names are derived from information that is itself predictable. If an attacker can guess what name a victim's application will try to use for a storage bucket, the attacker can create a bucket with that exact name first in their own project. When the victim's application later tries to create or access that bucket, it finds one that already exists and assumes it is valid. The SDK never checked who actually owned it.
This technique is called bucket squatting. It is the same concept as domain squatting, just applied to cloud storage namespaces. The victim's SDK silently uploads data to infrastructure the attacker controls, and the victim has no idea.
Pickle Deserialization
Python's pickle module is the standard way to serialize Python objects, converting a trained model object into a file that can be saved, transferred, and loaded later. Most ML practitioners use it constantly, often through wrapper libraries like joblib. It is practical and convenient.
The dangerous part is what happens during deserialization. When Python loads a pickle file, it can execute code as part of the reconstruction process. This is by design; certain Python objects need to run initialization logic when they are restored. But it means that if you load a pickle file that someone else has tampered with, that file can run arbitrary code on your machine the moment it is loaded. No prompt. No warning. The execution happens automatically inside joblib.load() or pickle.load().
Python's own documentation has warned about this for years: do not unpickle data from untrusted sources. In practice, plenty of ML pipelines do exactly that without realizing it, because they have assumed their storage layer is trusted. This is a core concern in vulnerability management for AI systems; serialization risk is still widely underestimated across the industry.
Race Conditions in Cloud Pipelines
A race condition happens when the security of a system depends on two events happening in a specific order, and an attacker can influence that order. In this context, Vertex AI's service agent (P4SA) reads the staged model artifact from the bucket at some point after the developer uploads it. That gap between upload and consumption is a window.
Unit 42 measured this window at roughly 2.5 seconds. That is enough time to detect the upload and replace the legitimate model with a malicious one, if you have automated the response fast enough. Polling would be too slow. But a Cloud Function that triggers on the storage upload event can react in under 800 milliseconds.
How the Vulnerability Was Found
The Unit 42 researchers were specifically investigating trust boundaries inside AI infrastructure. They were asking a question that does not get asked enough: when a managed AI platform does things on your behalf, what exactly does it trust, and is that trust warranted?
What made this research notable beyond the findings themselves was the methodology. The team incorporated a large language model into the code analysis workflow to accelerate discovery. Rather than manually reading through thousands of lines of SDK source code looking for patterns that might indicate misplaced trust, they used the LLM to iteratively narrow the focus, identifying where user-controlled inputs flowed into cloud resource names, where those names were used without validation, and which code paths connected user-facing APIs to backend infrastructure provisioning.
The researchers noted that analysis, which once took days, could be done significantly faster with this approach. This is an important signal for the industry. As AI tools get better at reading code, the timeline between a new SDK release and the discovery of vulnerabilities in it is going to compress. Security teams need to be thinking about this when they consider AI-driven red teaming and automated code review as part of their ongoing programs.
The specific function they found was stage_local_data_in_gcs() inside gcs_utils.py. The bucket name was constructed like this:
staging_bucket_name = project_id + "-vertex-staging-" + location
Entirely deterministic. Entirely predictable. And the SDK only checked whether the bucket existed — it never asked who owned it.
The Complete Attack Chain, Phase by Phase
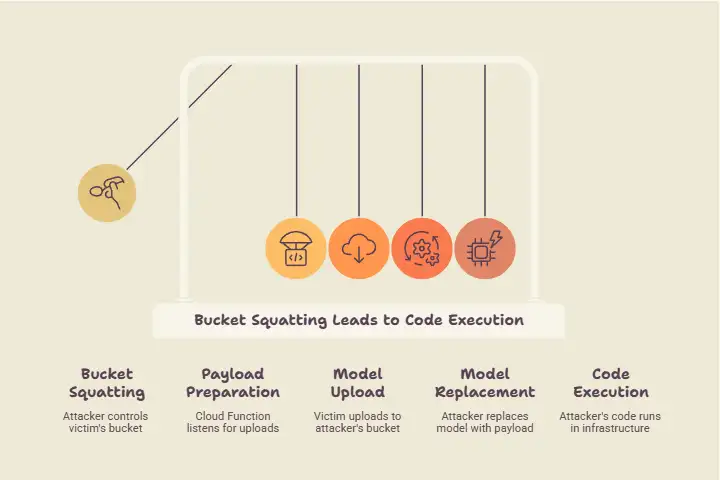
Here is how the full attack unfolds, from initial setup to code execution inside Google's serving infrastructure.
Phase 1: Bucket Squatting The attacker looks up or finds the victim's Google Cloud project ID. They predict the staging bucket name using the formula project-id-vertex-staging-region. They create that bucket in their own GCP account and configure its IAM permissions to allow both the victim's SDK uploads and the Vertex AI service agent's read access. The bucket now exists under attacker control, and any future attempt by the victim's SDK to use that name will silently resolve to the attacker's bucket.
Phase 2: Preparing the Payload The attacker deploys a Cloud Function in their own project that listens for the google.storage.object.finalize event on the squatted bucket. This event fires the moment any file is uploaded. The attacker also prepares a weaponized model file, a joblib-serialized object that overrides Python's reduce method to execute arbitrary code when deserialized. The payload is designed to reach out to the Google Cloud metadata server and extract OAuth credentials.
Phase 3: Victim Uploads the Model The victim developer runs their normal workflow. They call Model.upload() through the Vertex AI SDK. They have not set an explicit staging bucket. The SDK builds the bucket name deterministically, finds the attacker's bucket already there, and proceeds without any warning. The legitimate model artifacts are silently uploaded to attacker-controlled storage.
Phase 4: Model Replacement (The Race) The Cloud Function detects the upload almost immediately. Unit 42's measurements show the timeline: upload at T+0 ms, Cloud Function detection at T+804 ms, replacement complete at T+1,433 ms, and Vertex AI's P4SA reading the file at T+2,460 ms. The attacker's function replaces the legitimate model with the malicious payload well before Google's service agent ever touches it. The race is won.
Phase 5: Deployment The victim deploys the model to a Vertex AI prediction endpoint using their standard deployment process. No integrity checks exist on the staged artifacts. The poisoned model is treated as valid. The deployment completes successfully. The victim sees no error, no alert, and no indication that anything has gone wrong.
Phase 6: Remote Code Execution When the serving container starts, it loads the model using joblib.load(). Python's pickle deserialization executes the attacker's payload automatically during the load process before any validation, before any inference, before any other logic runs. The attacker's code is now running inside Google's infrastructure, in a container the victim trusts completely.
The attack required no credentials to the victim's project, no phishing, no insider access, and no prior compromise of any kind. The only input was a project ID that in many organizations is publicly visible in documentation, GitHub repos, or GCP resource URLs.
What Happened After Code Execution
The researchers built their proof-of-concept payload to demonstrate the realistic blast radius of a successful exploit. The results went well beyond what most people would expect from a model upload vulnerability.
The first thing the payload did was query the Google Cloud metadata server, the internal endpoint available to any process running inside a GCP environment. This returned a service account OAuth token belonging to the Platform Service Agent (custom-online-prediction@[tenant-project].iam.gserviceaccount.com). Critically, this token carried the cloud-platform scope, the broadest possible level of access.
With that token, the researchers found they could access other models deployed in the same Google-managed tenant project. This included full TensorFlow model files with trained weights and models belonging to other customers sharing the same tenant infrastructure. That is cross-tenant model theft.
They could also enumerate BigQuery datasets, tables, and access control lists. They could retrieve GKE cluster names, internal container image paths, and deployment metadata from the tenant environment. This is the kind of threat intelligence an attacker would use to plan further lateral movement, understanding the full shape of the environment before moving deeper.
The combination of capabilities, RCE, credential theft, cross-deployment access, and tenant intelligence significantly exceeded what the researchers initially expected. They had gone in looking for model poisoning. They found a pathway into Google's internal infrastructure.
This is exactly the kind of scenario that makes incident response and recovery planning so critical for teams running AI workloads on managed cloud platforms. When the compromise happens inside a serving container you do not directly manage, detection is hard and containment is harder.
Five Security Design Failures Behind This Flaw
The Pickle in the Middle vulnerability was not a single mistake. It was the result of several independent design decisions that each seemed reasonable in isolation but became catastrophic in combination.
Failure 1: Predictable Resource Naming
The staging bucket name was entirely derived from public information: the project ID and the deployment region. There was no randomness, no UUID, no unpredictable component. Predictable resource names in shared global namespaces are a well-understood vulnerability class in cloud environments. This was an instance of it built directly into a popular SDK used by a large number of ML teams.
Failure 2: No Ownership Validation
The SDK checked whether the bucket existed. It did not check whether the bucket belonged to the caller's project. These are completely different questions. A bucket's existence is a binary fact. Its ownership is a trust relationship. The SDK conflated them, and that conflation was the core of the exploit.
Failure 3: Trusting External Storage Without Verification
The Vertex AI serving infrastructure trusted whatever it found in the staging bucket. There was no mechanism to confirm that the artifact had been placed there by an authorized party, that it had not been modified after upload, or that it matched what the developer originally intended to deploy. This is a fundamental supply chain security gap, treating a storage location as a trust boundary when it never was one.
Failure 4: Unsafe Deserialization in a Serving Pipeline
Loading a pickle file in a production serving environment is inherently risky. The Python documentation has warned against deserializing untrusted pickle data since the early days of the language. In a cloud-serving pipeline where the storage layer can be influenced by external parties, the pickle format creates a direct path from external manipulation to code execution. Safer alternatives like ONNX and Safetensors exist specifically for this reason.
Failure 5: No Artifact Integrity Verification
There were no cryptographic signatures on model artifacts. No hash validation between upload and consumption. No provenance tracking that would let the serving layer verify the chain of custody from the developer's local machine to the deployed endpoint. A malicious swap was invisible to the entire pipeline because the pipeline had no way to detect it. This is the kind of gap that security testing for AI pipelines needs to specifically probe for.
Google's Response and the Fix Timeline
Unit 42 reported the vulnerability through Google's Vulnerability Reward Program on March 5, 2026. Google's response was fast and taken seriously.

Second and final fix deployed in v1.148.0: bucket ownership verification added.
The first fix addressed predictability. By appending a random UUID to the staging bucket name, Google eliminated the ability to guess the bucket ahead of time. The format changed from project-staging-region to something like project-staging-region-a3f7c2b1. An attacker cannot pre-register what they cannot predict.
The second fix addressed the underlying design flaw. The SDK now verifies that the staging bucket belongs to the caller's project before using it. Even if an attacker somehow predicted the new randomized name, the ownership check would block the attack. This was the more important fix; it closed the vulnerability class, not just the specific instance.
No CVE had been officially assigned by either Unit 42 or Google's Vertex AI security bulletins at the time of the original disclosure, though related research by Focal Security has tracked the Vertex AI variant of this vulnerability class as CVE-2026-2473 (VertexSquat).
What You Should Do Right Now
If your team uses the Vertex AI Python SDK, the response is straightforward but requires checking everywhere the SDK is installed, not just production services.
Update the SDK to v1.148.0 or later
This is the non-negotiable first step. The vulnerable logic lives in the client-side SDK, which means notebooks, CI/CD jobs, training pipelines, and local development environments are all in scope, not just deployed services. Run the upgrade everywhere.
pip install google-cloud-aiplatform>=1.148.0
Explicitly Define Staging Buckets
Do not rely on the SDK's automatic bucket selection. Specify a bucket you control when uploading models. This removes the automatic naming logic from the equation entirely and keeps your artifacts on infrastructure you have verified.
model = aiplatform. Model.upload(
display_name="my-model",
artifact_uri="gs://my-models/my-model/",
staging_bucket="gs://my-trusted-staging-bucket"
)
Audit Your Existing Bucket Permissions
Review the IAM policies on any GCS buckets used by your Vertex AI workflows. Remove all authenticated users and any other overly broad access grants. Only the identities that genuinely need access to model artifacts should have it. This is a foundational part of endpoint security hygiene extended to cloud storage resources.
Monitor Model Artifact Events
Set up alerting on your staging buckets for unexpected write and overwrite events. Any model artifact being modified after the initial upload, especially in the seconds before a deployment, is a signal worth investigating. This kind of behavioral monitoring is part of what good extended detection and response programs cover for cloud environments.
Move Away from Pickles Where Possible
For models where you control the format, consider switching to ONNX or Safetensors. Both formats lack the code execution capability that makes pickle dangerous in a pipeline where artifact integrity cannot be fully guaranteed. Where a pickle is unavoidable, treat the artifact as untrusted and validate its checksum and provenance before loading. This also connects directly to the AI security standards conversation: artifact integrity is increasingly becoming a baseline expectation.
Conduct a Supply Chain Security Review of Your AI Pipelines
Think through every point in your model training and deployment workflow where an external party could influence what gets loaded. Staging buckets, model registries, pre-trained model downloads, and third-party dataset sources are all potential injection points. A structured gap assessment focused on your AI/ML pipeline is a practical starting point if your team has not done one recently.
Also consider whether your organization's current vulnerability management process covers SDK dependencies in ML environments. Many teams track web application libraries carefully but have a blind spot for the Python packages their data science teams use in production pipelines.
The Bigger Picture for AI Security
There is a tendency to think of AI security primarily in terms of model behavior, prompt injection, jailbreaks, output manipulation, and adversarial examples. Those are real problems. But the Pickle in the Middle vulnerability points at a different and arguably more immediate risk: the infrastructure layer underneath the model.
AI pipelines are software supply chains. The models your team trains and deploys are artifacts in the same sense that compiled binaries are artifacts. They can be tampered with. They can carry malicious payloads. They can be substituted at transit points. And unlike traditional software, ML artifacts often use serialization formats that execute code on load by design.
The attack surface for a modern AI workload includes the SDK versions your developers use, the cloud storage buckets where artifacts transit, the service accounts that move those artifacts around, the deserialization logic in the serving container, and the trust assumptions baked into the managed platform beneath all of it. A comprehensive approach to securing this requires thinking across all of those layers simultaneously.
"Our research shows that cloud security extends into the developer toolchain and machine learning model lifecycle. The vulnerability that we discovered demonstrates how seemingly minor design flaws can lead to a critical security issue." - Unit 42, Palo Alto Networks
The fact that researchers used an LLM to accelerate the discovery of this vulnerability is also worth sitting with. The same technique is available to attackers. The window between a new SDK release and the automated discovery of vulnerabilities in it is shrinking. This puts more pressure on vendors to conduct a rigorous security review of SDK design decisions before release and more pressure on teams to treat their ML dependencies with the same scrutiny they apply to their application code. Proactive cyber resilience assessment for AI pipelines is no longer optional for organizations with significant ML workloads.
The Pickle in the Middle research also connects to a broader pattern that security researchers have been tracking: bucket squatting as an attack class is not unique to Vertex AI. The same Focal Security research that assigned CVE-2026-2473 to the Vertex AI variant also documented similar flaws in Gemini Enterprise (CVE-2026-1727, GeminiSquat) and Cloud Run (MountSquat). The root cause of predictable resource names in shared global namespaces without ownership validation is a recurring architectural mistake across cloud services. It will keep appearing until cloud providers build ownership validation into the fundamental abstractions of cloud storage, not just specific SDKs.
For organizations thinking through how to proactively identify these kinds of risks before a researcher or attacker finds them, the answer involves several things working together: penetration testing that specifically covers AI and ML infrastructure, attack surface management that includes SDK dependencies and cloud storage resources, and threat intelligence programs that track emerging vulnerability classes in AI platforms. The online threat exposure monitoring discipline is also expanding to include monitoring for squattable cloud resource names, in the same way domain monitoring has long been standard practice.
This is not a solved problem. The fix Google shipped is correct and meaningful. But the underlying design pattern of trusting resource names as identity, treating storage as a trust boundary without validating ownership, still exists in many places across cloud platform ecosystems. Security teams should be asking their cloud vendors and their own developers alike, "Where else are we doing this?"
Official References
1. Unit 42, Palo Alto Networks: Pickle in the Middle: Hijacking Vertex AI Model Uploads for Cross-Tenant RCE (Primary Research Report)
2. Focal Security: Kicking the Bucket: Critical RCE and Cross-Tenant Exploits in 3 Different GCP Products (CVE-2026-2473, VertexSquat)
4. CSO Online: Google's Vertex AI SDK Could Allow RCE Through Bucket Squatting
6. Google Vulnerability Reward Program: Google Cloud VRP Guidelines